Data quality is everything when it comes to machine learning or data-driven applications in geotechnical engineering (or any field, actually).
No matter how advanced your model is, if the data isn’t solid, the results won’t be either.
That’s why I believe the first step in applying AI to geotechnical problems is to truly understand the nature of our data. After all, geotechnical data isn’t like financial data or medical records, it has its own unique challenges.
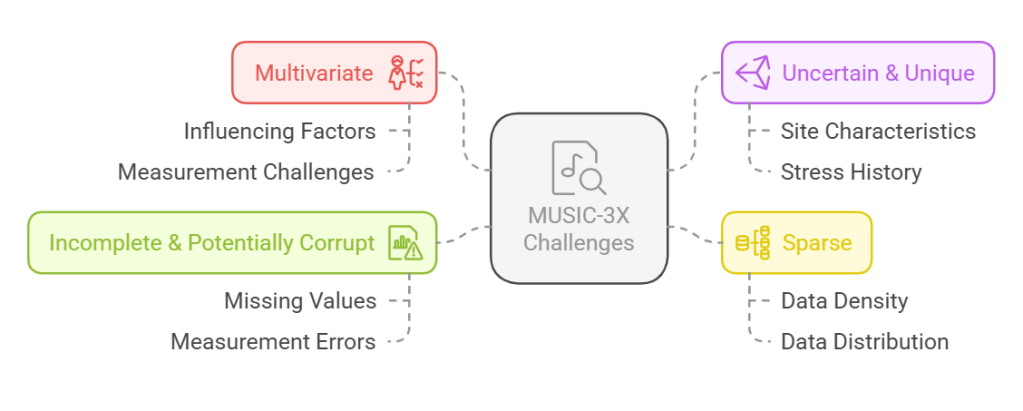
For me, a great way to remember these challenges is MUSIC-3X, a concept proposed by Professor K.K. Phoon in several research papers (You can Google it too, but I put one of the references below1). It stands for:
Multivariate: So many factors influence soil behavior, including ones we don’t even measure.
Uncertain & Unique: I’m sure you agree on this! I mean, how confident are we in any geotechnical measurement? Even with a perfectly retrieved Shelby tube sample and a flawless lab test, does that value truly reflect in-situ conditions? Plus, every site has its own stress history and characteristics, making it hard to generalize findings from one location to another.
Sparse: Geotechnical data is always limited. We rarely have the density of data we’d like.
Incomplete & Potentially Corrupt – Missing values, measurement errors, sampling disturbance… you name it!
And 3X? That’s for the three-dimensional spatial variability of soils
When you think about it, MUSIC-3X perfectly captures what we, as geotechnical engineers, already know. And when applying machine learning, keeping these challenges in mind is critical.
Okay, Geotechnical Data is MUSIC, what’s next?
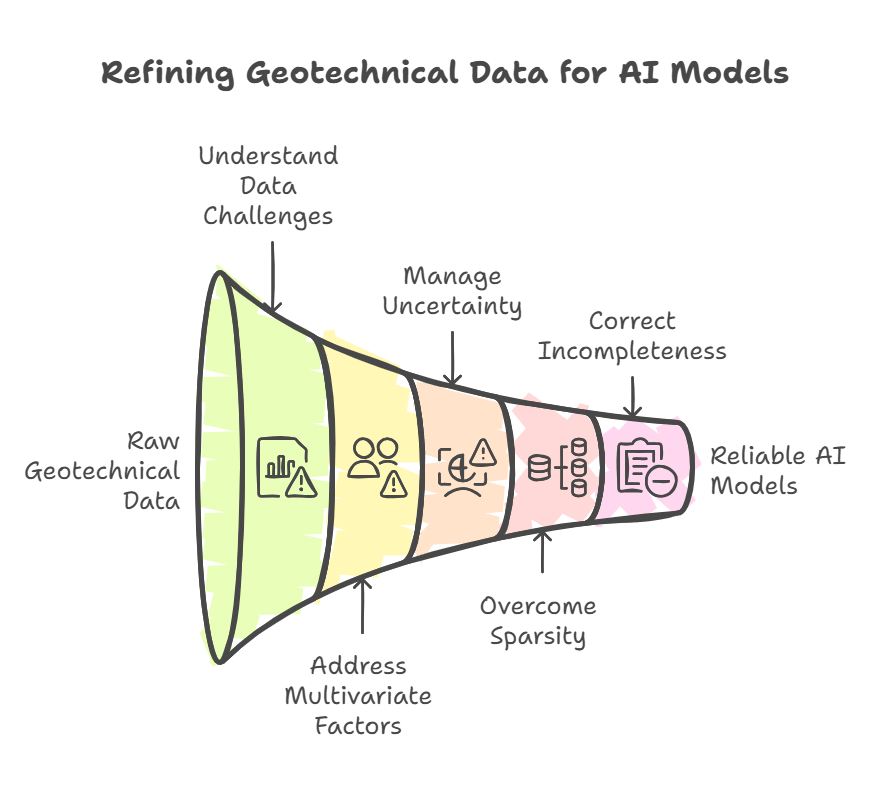
The better we assess and clean our geotechnical data, the more reliable and meaningful our data-driven models become. It’s that simple.
Depending on project size, there should be a structured approach to evaluating data coherence and consistency. An expert system that not only checks for gaps but also interprets missing information based on sound engineering judgment. Bringing in multiple perspectives ensures data quality is at its highest.
The plot below captures this idea: first, we understand the data and the problem at hand. Then, we systematically address uncertainty, correctness, and sparsity, paving the way for more robust and trustworthy geotechnical machine learning models.
What’s your take on this?

Leave a comment