At the GeoCongress 2023 conference in LA, I had an interesting conversation with a geotechnical engineer about a Bayesian correlation model we developed.
The model correlated cone penetration tip resistance with standard penetration test (SPT) blow counts in sandy soils, using 220 high-quality data points from previous research.
His reaction? “Wait, just 220 points? And you’re calling this machine learning?”
I defended my work, of course, the research was solid, peer-reviewed, and ultimately published. But his reaction got me thinking:
How much data is enough?
Is it 100? 500? A million? What’s the magic number?
The Data Threshold Dilemma
Fast forward two years, and I’ve reviewed several Machine Learning-based geotechnical papers. Some used as few as 15 data points, while others had a few thousand.
So, where do we draw the line?
To answer this, I think of it as a two-step process:
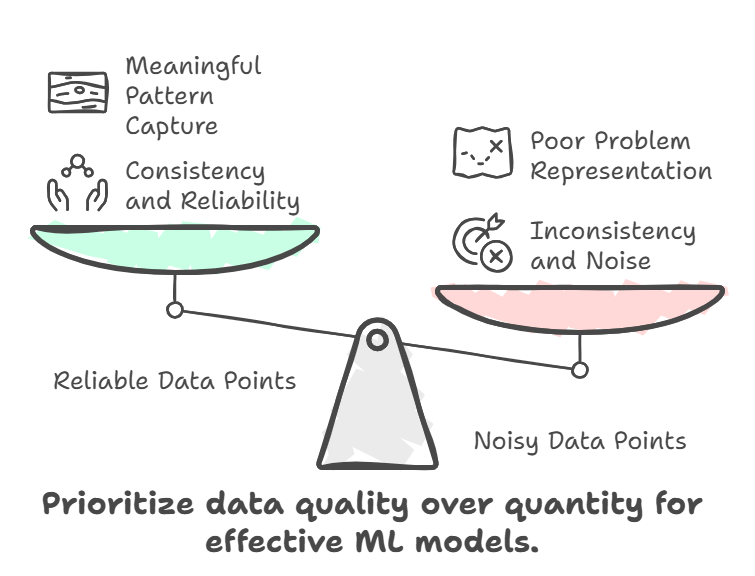
- Data Reliability: You might remember my article, Geotechnical Data is MUSIC (if not, check the link below!1). Before counting data points, we need to assess their quality, are they consistent, reliable, and representative of the real-world problem?
- Geotechnical Knowledge & Context: Data volume alone doesn’t define a model’s success. Instead, we must evaluate whether the data adequately represents the problem and whether it captures meaningful patterns.
I’d take 100 reliable data points over 2,000 noisy, inconsistent ones any day.
A Guide to Data Count
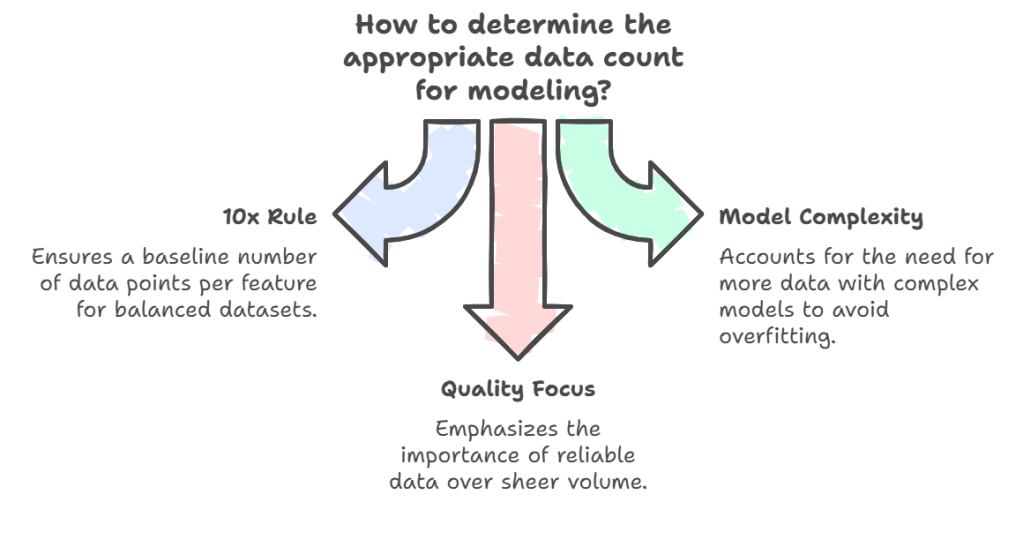
There’s no one-size-fits-all rule, but these three principles can serve as a starting point:
- The “10x Rule” (Not so sure about that!): A common guideline suggests you need at least 10 data points per feature. If your dataset has 10 features, a reasonable baseline would be 100 data points.
- Model Complexity Matters: Deep learning models (like ANNs) are data-hungry. The more complex the model, the more data you need to avoid overfitting and ensure meaningful generalization.
- Quality Over Quantity: More data doesn’t always mean better results. Garbage in, garbage out, if the data is unreliable, even millions of points won’t save the model.
The Discussion is Open
This topic is still evolving. Data requirements vary depending on the problem, scenario, and expertise applied. I’ll probably update this post as we refine better frameworks for assessing data sufficiency.
But for now, the key takeaway is this:
More data is great, but reliable data is essential.
What do you think? Have you faced challenges with data sufficiency in ML models?


Leave a comment